Ingeotec at Rest-Mex: Bag-of-Words Classifiers
IberLEF 2023, September 2023, Jaén, Spain
INGEOTEC research group

GitHub: https://github.com/INGEOTEC
WebPage: https://ingeotec.github.io/
Our approach: EvoMSA 2.0

EvoMSA’s documentation (https://evomsa.readthedocs) Papers (Graff et al. 2020) (Tellez et al. 2017)
SBoW
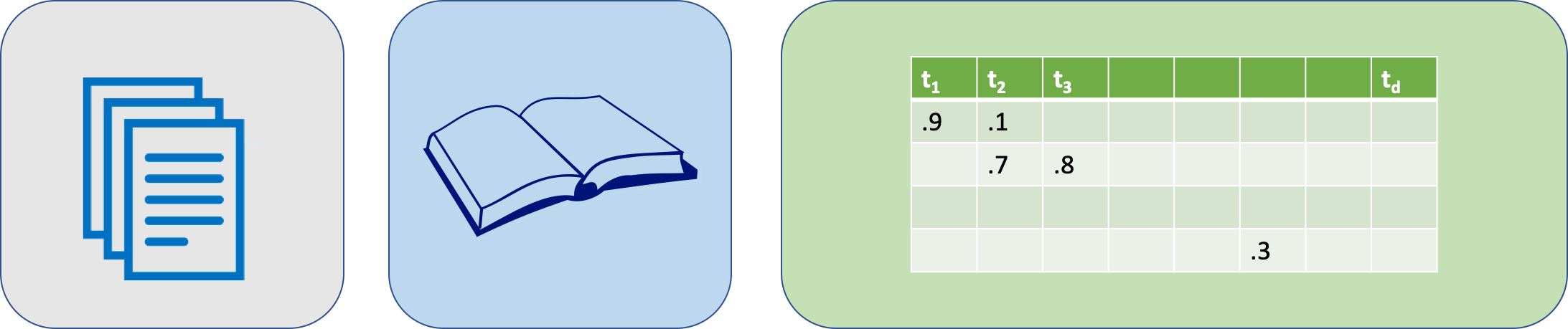
Dense BoW (stacking)
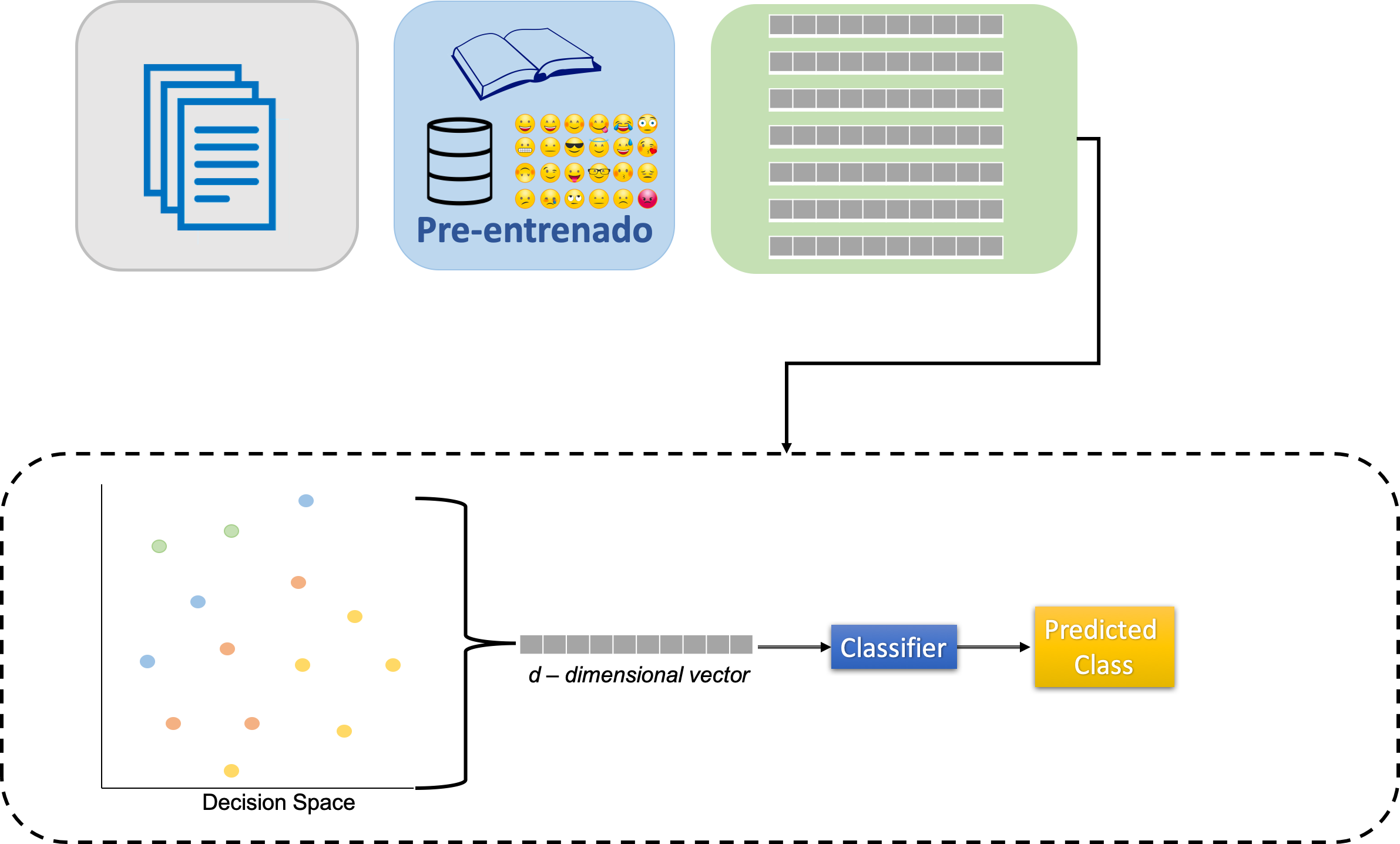
Stacking: All models aggregated are used according to their weights for producing an output, the final classification.
Conclusions (continued…)
- Our results show that developing competitive models for violent event identification is possible using only text-based features and, even more, bag-of-words-based models.
- Explainability of the model (with a simple bow outstanding results). Simplest solution
- Fast solution (in training and test), low computational resources. Dense representation using at most 100 million tweets.
