import numpy as np
import pandas as pd
from matplotlib import pylab as plt
import seaborn as sns
from CompStats.metrics import recall_score
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.datasets import load_breast_cancer
from sklearn.datasets import fetch_openml
from sklearn.preprocessing import Normalizer
from sklearn.pipeline import make_pipeline
from sklearn.cluster import KMeans
from sklearn import decomposition
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import tree1 Introducción
El objetivo de la unidad es explicar el área de aprendizaje computacional, los diferentes tipos de aprendizaje que la componen, la metodología general del área y su relación con otras áreas del conocimiento.
Paquetes usados
1.1 Aprendizaje Computacional
Según la descripción de Langley (1986), el aprendizaje computacional es una rama de la Inteligencia Artificial (IA) que estudia los enfoques computacionales capaces de aprender y mejorar su rendimiento con el tiempo. Inicialmente, el campo se centraba en el desarrollo de representaciones simbólicas, al igual que la IA, aunque también permitía representaciones numéricas. Actualmente, el enfoque ha cambiado, privilegiando las representaciones numéricas sobre las simbólicas. Este documento se centra exclusivamente en las representaciones numéricas.
Actividad
Leer la carta editorial de Langley (1986) para conocer la visión que se tenía de aprendizaje computacional en esa época y contrastarla con la visión actual.
Según Breiman (2001), al analizar datos con valores de entrada y respuesta, existen dos objetivos principales: predecir la respuesta de futuros eventos y extraer conocimiento del proceso o fenómeno. Estos objetivos han dado origen a dos enfoques en el modelado de datos: la cultura del modelado de datos y la cultura del modelado de algoritmos.
En la cultura del modelado de datos, se asume que los datos provienen de una función que depende de los valores de entrada, un conjunto de parámetros y ruido. Utilizando los datos, se estiman los parámetros y, si los datos cumplen con las condiciones impuestas a la función, se puede conocer el procedimiento que genera los datos, logrando así la segunda meta. Con los parámetros y la estructura de la función, es posible hacer predicciones de futuros eventos (primera meta).
En la cultura del modelado de algoritmos, no se asume ninguna estructura para el sistema que genera los datos. El enfoque es diseñar un algoritmo que replique la respuesta dada las entradas. Dado que no se asume ningún modelo particular, obtener conocimiento del sistema no es una prioridad. En cambio, la prioridad es encontrar el algoritmo que mejor reproduzca los datos, desarrollando diversas estrategias para medir el rendimiento del algoritmo y estimar su comportamiento en diferentes escenarios. El área de aprendizaje computacional se encuentra en esta segunda cultura.
Actividad
Leer el artículo de Breiman (2001) para profundizar en las ventajas y desventajas de cada una de las culturas y como estas influyen en la forma de abordar un problema. En este momento no es necesario detenerse en la parte técnica de los algoritmos descritos en el artículo.
Existen diferentes tipos de aprendizaje computacional, los mas comunes son: aprendizaje supervisado, aprendizaje no-supervisado y aprendizaje por refuerzo. En aprendizaje supervisado se crean modelos partiendo de un conjunto de pares, entrada y salida, donde el objetivo es encontrar un modelo que logra aprender esta relación y predecir ejemplos no vistos en el proceso, en particular a esto se le conoce como inductive learning. Complementando este tipo de aprendizaje supervisado se tiene lo que se conoce como transductive learning, en el cual se cuenta con un conjunto de pares y solamente se requiere conocer la salida en otro conjunto de datos. En este segundo tipo de aprendizaje todos los datos son conocidos en el proceso de aprendizaje.
Aprendizaje no-supervisado es aquel donde se tiene un conjunto de entradas y se busca aprender alguna relación de estas entradas, por ejemplo, generando grupos o utilizando estas entradas para hacer una transformación o encontrar un patrón.
Finalmente aprendizaje por refuerzo es aquel donde se tiene un agente que tiene que aprender como interactuar con un ambiente. La interacción es tomando una acción en cada diferente estado del ambiente. Por ejemplo, el agente puede ser un jugador virtual en un juego de ajedrez entonces la acción es identificar y mover una pieza en el tablero, el objetivo de ganar la partida. La característica de aprendizaje por refuerzo es que el agente va a recibir una recompensa al final de la interacción con el ambiente, e.g., final del juego y el objetivo es optimizar las acciones para que la recompensa sea la mayor posible.
El área de aprendizaje computacional ha tenido un crecimiento importante en los últimos años, algunos ejemplos del impacto de área se pueden encontrar en artículos publicados en la revista de la editorial Nature. Por ejemplo, en el área médica en específico en Cardiología Hannun et al. (2019) propone una metodología para detectar arritmias o en dermatología Esteva et al. (2017) propone un algoritmo para la detección de cancer.
Cabe mencionar que los tres tipos de aprendizaje no son excluyentes uno del otro, comúnmente para resolver un problema complejo se combinan diferentes tipos de aprendizaje y otras tecnologías de IA para encontrar una solución aceptable. Probablemente una de las pruebas más significativas de lo que puede realizarse con aprendizaje automático es lo realizado por AlphaGo descrito por Silver et al. (2016) y en Silver et al. (2017) se quitan una de las restricciones originales, la cual consiste en contar con un conjunto de jugadas realizadas por expertos.
En el área de aprendizaje, hay una tendencia de utilizar plataformas donde diferentes empresas u organismos gubernamentales o sin fines de lucro, ponen un problema e incentivan al publico en general a resolver este problema. La plataforma sirve de mediador en este proceso. Ver por ejemplo https://www.kaggle.com.
En el ámbito científico también se han generado este tipo de plataformas aunque su objetivo es ligeramente diferente, lo que se busca es tener una medida objetiva de diferentes soluciones y en algunos casos facilitar la reproducibilidad de las soluciones. Ver por ejemplo http://codalab.org.
1.2 Metodología General en Aprendizaje Supervisado y No Supervisado
Antes de continuar con la descripción de los diferentes tipos de aprendizaje es importante mencionar la metodología que se sigue en los problemas de aprendizaje supervisado y no supervidado
- Todo empieza con un conjunto de datos \(\mathcal D\) que tiene la información del fenómeno de interés.
- Se selecciona el conjunto de entrenamiento \(\mathcal T \subseteq \mathcal D\).
- Se diseña un algoritmo, \(f\), utilizando \(\mathcal T\).
- Se utiliza \(f\) para estimar las características modeladas.
- Se mide el rendimiento de \(f\).
1.3 Aprendizaje No Supervisado
Iniciamos la descripción de los diferentes tipos de aprendizaje computacional con aprendizaje no-supervisado; el cual inicia con un conjunto de elementos. Estos tradicionalmente se puede transformar en conjunto de vectores, i.e. \(\mathcal D = \{ x_1, \ldots, x_N \}\), donde \(x_i \in \mathbb R^d\). Durante este curso asumiremos que esta transformación existe y en algunos casos se hará explícito el algoritmo de transformación.
El objetivo en aprendizaje no supervisado es desarrollar algoritmos capaces de encontrar patrones en los datos, es decir, en \(\mathcal D\). Existen diferentes tareas que se pueden considerar dentro de este tipo de aprendizaje. Por ejemplo, el agrupamiento puede servir para segmentar clientes o productos, en otra línea también cabría el análisis del carrito de compras (Market Basket Analysis); donde el objetivo es encontrar la co-ocurrencias de productos, es decir, se quiere estimar la probabilidad de que habiendo comprado un determinado artículo también se compre otro artículo. Con esta descripción ya se podrá estar imaginando la cantidad de aplicaciones en las que este tipo de algoritmos es utilizado en la actualidad.
Regresando a la representación vectorial, existen casos donde se pueden visualizar los elementos de \(\mathcal D\), lo cuales están representados como puntos que se muestran en la Figura 1.1. Claramente esto solo es posible si \(x_i \in \mathbb R^2\) o si se hace algún tipo de transformación \(f: \mathbb R^d \rightarrow \mathbb R^2\), como se realizó en la figura.
Código
D, y = load_iris(return_X_y=True)
pca = decomposition.PCA(n_components=2).fit(D)
Dn = pca.transform(D)
Dn = np.concatenate((Dn, np.atleast_2d(y).T), axis=1)
df = pd.DataFrame(Dn, columns=['x', 'y', 'Clase'])
fig = sns.relplot(data=df, kind='scatter',
x='x', y='y')
fig.tick_params(bottom=False, top=False,
left=False, right=False,
labelbottom=False, labelleft=False)
fig.set(xlabel=None, ylabel=None)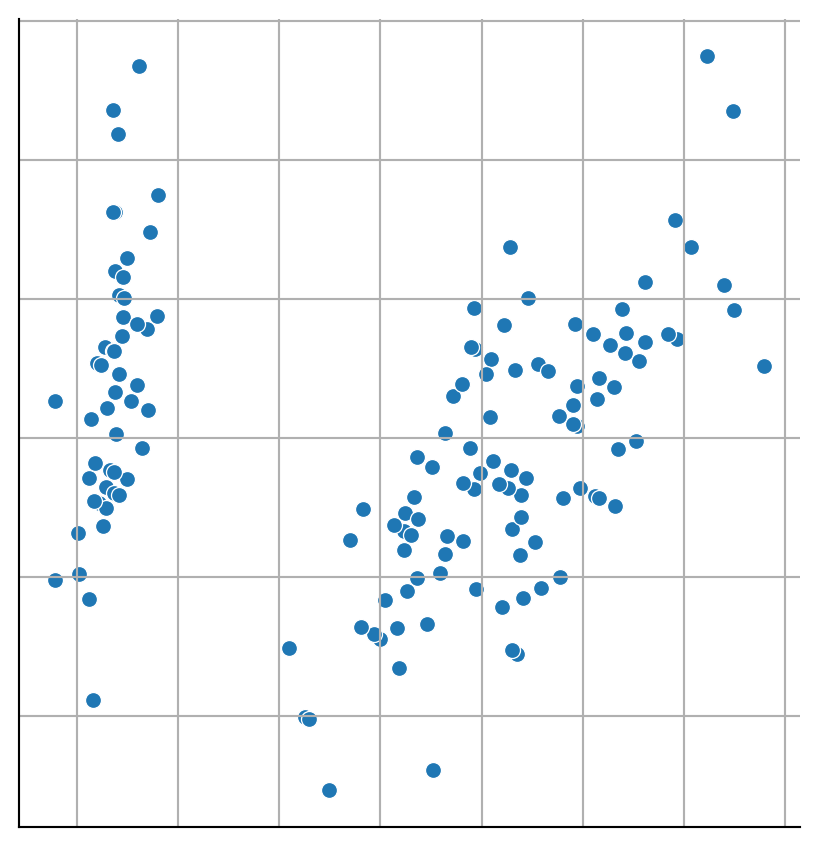
En la Figura 1.1 se pueden observar dos o tres grupos de puntos, entonces el objetivo sería crear el algoritmo que dado \(\mathcal D\) regrese un identificador por cada elemento, dicho identificador representa el grupo al que pertenece el elemento en cuestión. Esta tarea se le conoce como agrupamiento (Clustering). Asumiendo que se aplica un algoritmo de agrupamiento a los datos anteriores; entonces, dado que podemos visualizar los datos, es factible representar el resultado del algoritmo si a cada punto se le asigna un color dependiendo de la clase a la que pertenece. La Figura 1.2 muestra el resultado de este procedimiento.
Código
D, y = load_iris(return_X_y=True)
m = KMeans(n_clusters=3, n_init='auto').fit(D)
cl = m.predict(D)
pca = decomposition.PCA(n_components=2).fit(D)
Dn = pca.transform(D)
df = pd.DataFrame(Dn, columns=['x', 'y'])
df['Clase'] = y.astype(str)
df['Grupo'] = cl.astype(str)
fig = sns.relplot(data=df, kind='scatter',
x='x', y='y', hue='Grupo')
fig.tick_params(bottom=False, top=False,
left=False, right=False,
labelbottom=False, labelleft=False)
fig.set(xlabel=None, ylabel=None)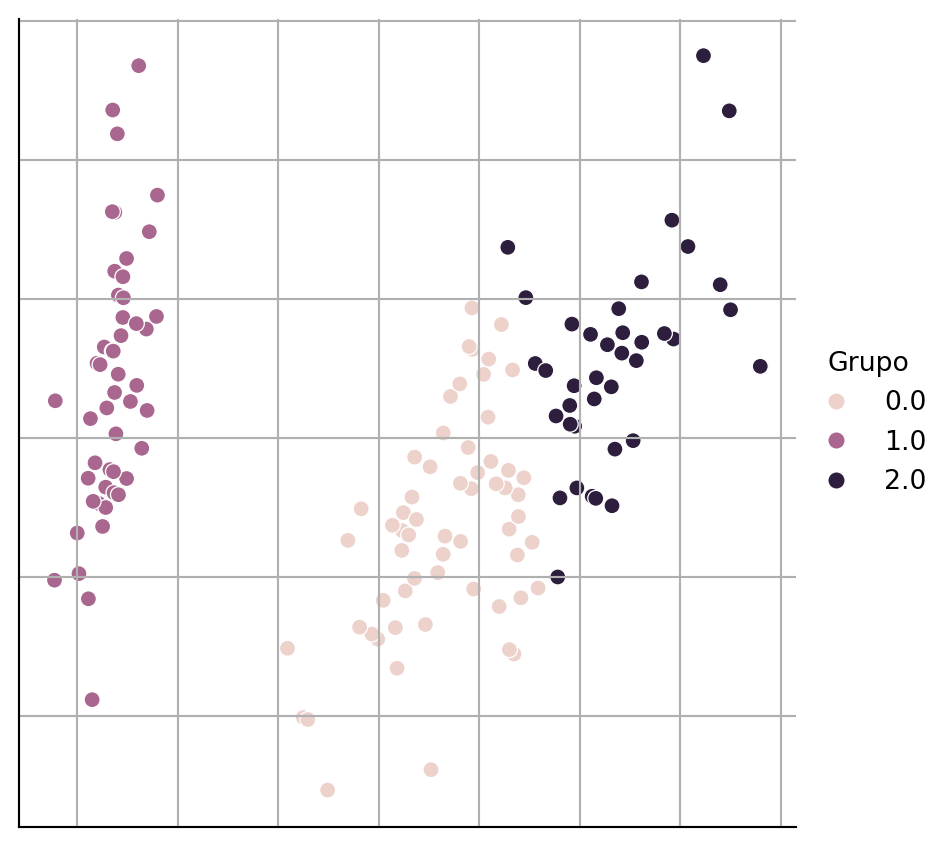
Se puede observar en la figura anterior, el algoritmo de agrupamiento separa los puntos en tres grupos, representados por los diferentes colores. Cabe mencionar que utilizando algún otro criterio de optimización se hubiera podido encontrar dos grupos, el primero de ellos sería el grupo de los puntos que se encuentran a la izquierda de la figura y el segundo sería el grupo formado por los grupos que se encuentran en el centro y a la derecha de la figura. Es importante recalcar que no es necesario visualizar los datos para aplicar un algoritmo de agrupamiento. En particular el ejercicio de visualización de datos y del resultado de agrupamiento que se muestra en la figuras anteriores tiene el objetivo de generar una intuición de lo que está haciendo un algoritmo de agrupamiento.
Actividad
Generar la figura anterior para el conjunto de datos de Breast Cancer Wisconsin (Sección B.3.1). Es necesario considerar que ese problema solamente tiene dos clases y el problema del Iris (Sección B.3.2) tiene tres clases, entonces se tienen que hacer las modificaciones para atender este cambio.
El procedimiento desarrollado debe de generar una figura similar a la mostrada en la Figura 1.3
1.4 Aprendizaje Supervisado
Aprendizaje supervisado inicia con un conjunto de pares, entrada y salida; la Figura 1.4 ilustra el mecanismo que genera estos pares, del lado izquierdo se tiene las variables medibles que entran al proceso o fenómeno que se desconoce y del lado derecho se mide la(s) variable(s) respuesta, es decir, la(s) salida(s) del sistema. En otras palabras se tiene \(\mathcal D = \{ (x_1, y_1), \ldots, (x_N, y_N )\}\), donde \(x_i \in \mathbb R^d\) corresponde a la \(i\)-ésima entrada y \(y_i\) es la salida asociada a esa entrada.
flowchart LR
Entrada([Entradas]) --> Proceso[Proceso / Fenómeno]
Proceso --> Salidas([Salidas])
Considerando que se desconoce el modelo del proceso o fenómeno que generó la respuesta y además que pueden existir variables de entrada que no son medibles, se puede definir el objetivo de aprendizaje supervisado como encontrar un algoritmo o función, \(f\), capaz de regresar la salida, \(y\), dada una entrada \(x\).
Los posibles fines de desarrollar la función \(f\) es por un lado predecir la salida dada una nueva entrada \(x\) y por el otro lado extraer conocimiento del proceso que asocia la respuesta de las variables de entrada (ver Breiman (2001)). Estos dos metas se pueden contraponer, es decir, extraer conocimiento implica una reducción en la calidad de la predicción y viceversa mejorar la calidad de predicción en general trae consigo una menor capacidad para entender el fenómeno generador de datos.
Existe una gran variedad de problemas que se puede categorizar como tareas de aprendizaje supervisado, solamente hay que recordar que en todos los casos se inicia con un conjunto \(\mathcal D\) de pares entrada y salida. En ocasiones la construcción del conjunto es directa, por ejemplo en el caso de que se quiera identificar si una persona será sujeta a un crédito, entonces el conjunto a crear esta compuesto por las características de las personas que se les ha otorgado un crédito y el estado final de crédito, es decir, si el crédito fue pagado o no fue pagado. En otro ejemplo, suponiendo que se quiere crear un algoritmo capaz de identificar si un texto dado tiene una polaridad positiva o negativa, entonces el conjunto se crea recolectando textos y a cada texto un conjunto de personas decide si el texto dado es positivo o negativo y la polaridad final es el consenso de varias opiniones; a este problema en general se le conoce como análisis de sentimientos.
La cantidad de problema que se pueden poner en términos de aprendizaje supervisado es amplia, un problema tangible en esta época y relacionado a la pandemia del COVID-19 sería el crear un algoritmo que pudiera predecir cuántos serán los casos positivos el día de mañana dando como entradas las restricciones en las actividades; por ejemplo escuelas cerradas, restaurantes al 30% de capacidad entre otras.
Los ejemplos anteriores corresponden a dos de las clases de problemas que se resuelven en aprendizaje supervisado estas son problemas de clasificación y regresión. Definamos de manera formal estos dos problemas. Cuando \(y \in \{0, 1\}\) se dice que es un problema de clasificación binaria, por otro lado cuando \(y \in \{0, 1\}^K\) se encuentra uno en clasificación multi-clase o multi-etiqueta y finalmente si \(y \in \mathbb R\) entonces es un problema de regresión.
Haciendo la liga entre los ejemplos y las definiciones anteriores, podemos observar que el asignar un crédito o la polaridad a un texto es un problema de clasificación binaria, dado que se puede asociar 0 y 1 a la clase positivo y negativo; y en el otro caso a pagar o no pagar el crédito. Si el problema tiene mas categorías, supongamos que se desea identificar positivo, negativo o neutro, entonces se estaría en el problema de clasificación multi-clase. Por otro lado el problema de predecir el número de casos positivos se puede considerar como un problema de regresión, dado que el valor a predecir difícilmente se podría considerar como una categoría.
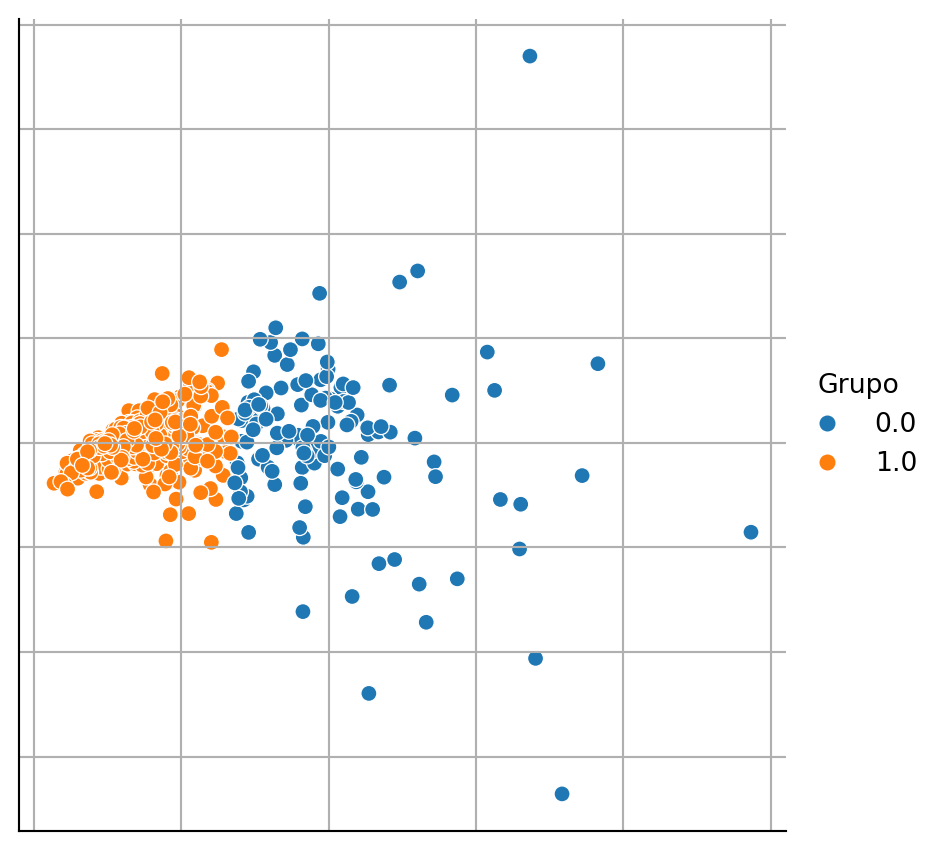
Al igual que en aprendizaje no supervisado, en algunos casos es posible visualizar los elementos de \(\mathcal D\), el detalle adicional es que cada objeto tiene asociado una clase, entonces se selecciona un color para representar cada clase. En la Figura 1.5 se muestra el resultado donde los elementos de \(\mathcal D\) se encuentra en \(\mathbb R^2\) y el color representa cada una de la clases de este problema de clasificación binaria.
Código
D, y = load_iris(return_X_y=True)
mask = y <= 1
D = D[mask]
y = y[mask]
pca = decomposition.PCA(n_components=2).fit(D)
Dn = pca.transform(D)
df = pd.DataFrame(Dn, columns=['x', 'y'])
df['Clase'] = ['P' if i else 'N' for i in y]
fig = sns.relplot(data=df, kind='scatter',
x='x', y='y', hue='Clase')
fig.tick_params(bottom=False, top=False,
left=False, right=False,
labelbottom=False, labelleft=False)
fig.set(xlabel=None, ylabel=None)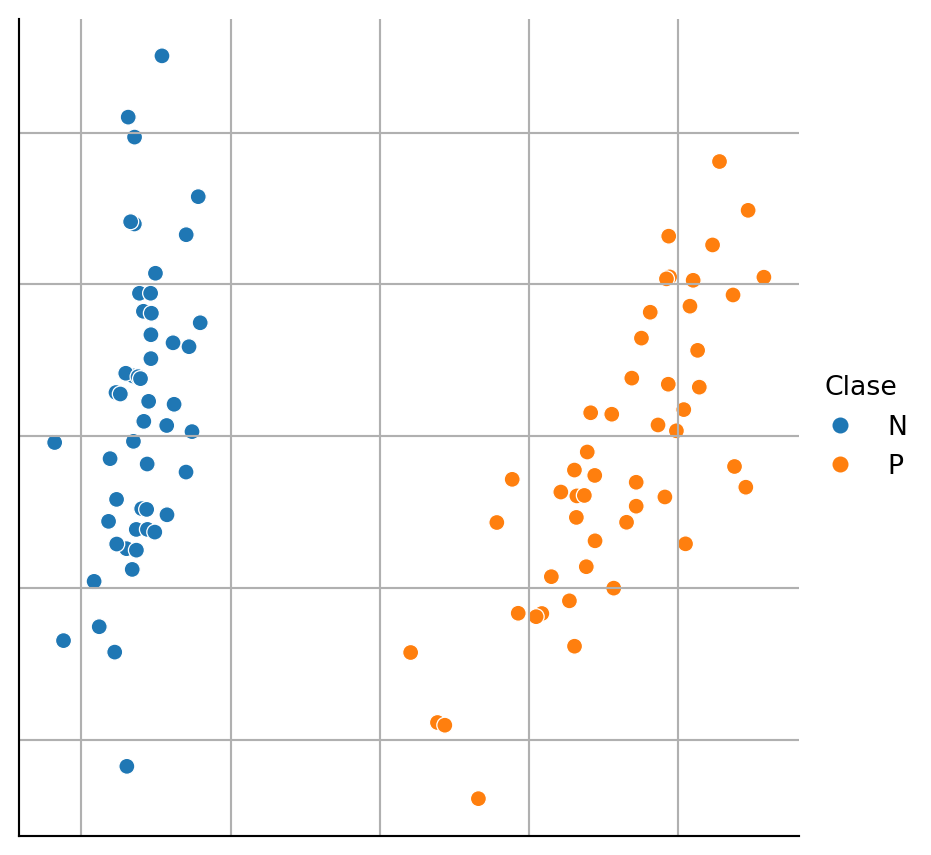
Actividad
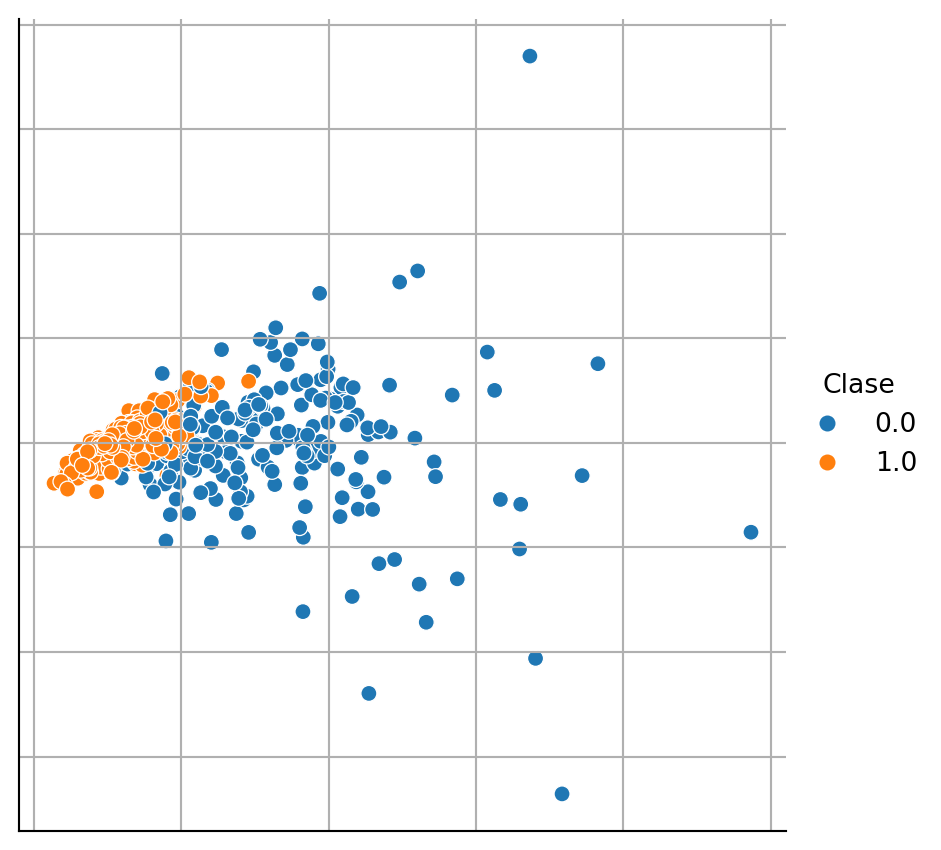
Generar la figura anterior para el conjunto de datos de Breast Cancer Wisconsin (Sección B.3.1). Como se mencionó, el problema tiene dos clases entonces no se necesita ningún tipo de transformación en el número de clases como se hizo en el ejemplo anterior. La Figura 1.6 muestra el resultado de la actividad.
Usando esta representación es sencillo imaginar que el problema de clasificación se trata en encontrar una función que separe los puntos naranjas de los puntos azules, como se pueden imagina una simple línea recta podría separar estos puntos. La Figura 1.7 muestra un ejemplo de lo que haría un clasificador representado por la línea; la clase es dada por el signo de \(ax + by + c\), donde \(a\), \(b\) y \(c\) son parámetros identificados a partir de \(\mathcal D\).
Código
D, y = load_iris(return_X_y=True)
mask = y <= 1
D = D[mask]
y = y[mask]
pca = decomposition.PCA(n_components=2).fit(D)
Dn = pca.transform(D)
linear = LinearSVC(dual=False).fit(Dn, y)
w_1, w_2 = linear.coef_[0]
w_0 = linear.intercept_[0]
df = pd.DataFrame(Dn, columns=['x1', 'x2'])
df['Clase'] = ['N' if i else 'P' for i in y]
g_0 = [dict(x1=x, x2=y, tipo='g(x)=0')
for x, y in zip(Dn[:, 0], (-w_0 - w_1 * Dn[:, 0]) / w_2)]
g = pd.DataFrame(g_0)
g['Tipo'] = 'g(x)=0'
df = pd.concat((df, g))
ax = sns.scatterplot(data=df, x='x1', y='x2', hue='Clase', legend=True)
sns.lineplot(data=df, x='x1', y='x2', ax=ax, hue='Tipo', palette=['k'], legend=True)
ax.tick_params(axis="both", which="both", bottom=False,
top=False, left=False, right=False,
labelbottom=False, labelleft=False)
ax.set(xlabel=None, ylabel=None)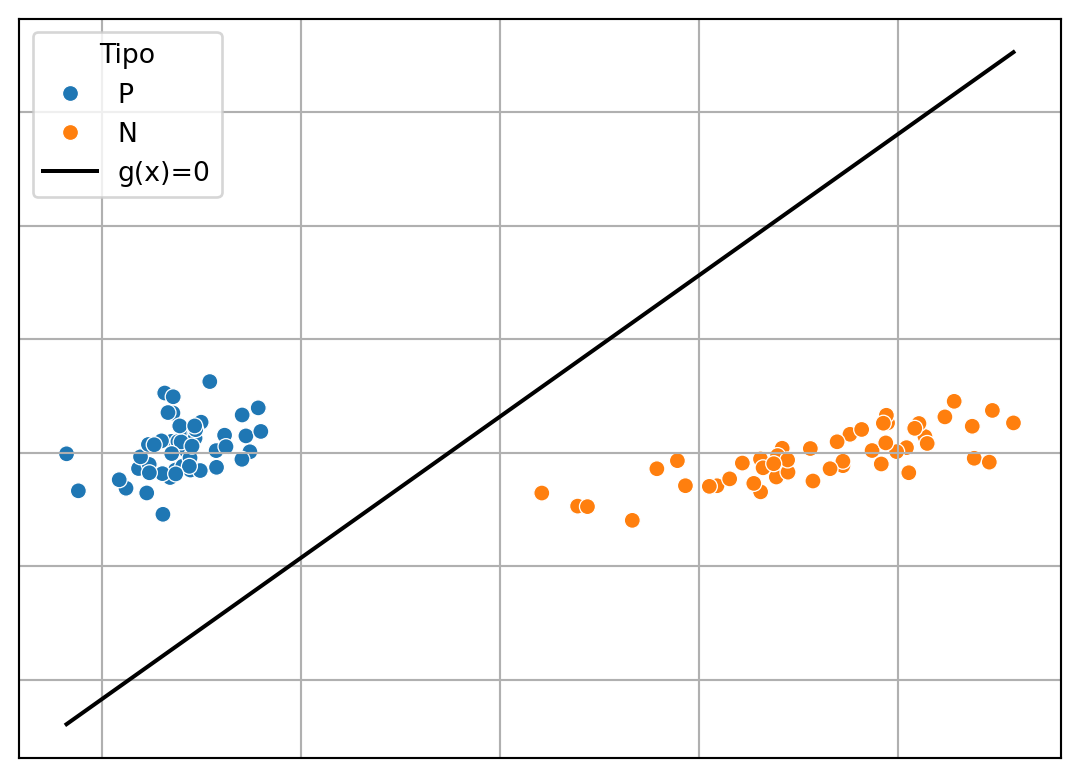
Siguiendo en esta misma línea, también es posible observar los puntos en un problema de regresión, solamente que en este caso un eje corresponde a las entradas, i.e. \(x,\) y el otro eje es la salida, i.e. \(y.\) La Figura 1.8 muestra un ejemplo de regresión, donde se puede observar que la idea es una encontrar una función que pueda seguir de manera adecuada los puntos datos.
Código
x = np.linspace(-1, 1, 100)
y = 12.3 * x**2 - 3.2 * x + 1.2
ym = np.random.normal(loc=0, scale=0.2, size=x.shape[0]) + y
df = pd.DataFrame(dict(x=x, y=y, ym=ym))
# sns.lineplot(data=df, x='x', y='y', legend=False, color='k')
fig = sns.scatterplot(data=df, x='x', y='ym', legend=False)
fig.tick_params(bottom=False, top=False,
left=False, right=False,
labelbottom=False, labelleft=False)
fig.set(xlabel='x', ylabel='y')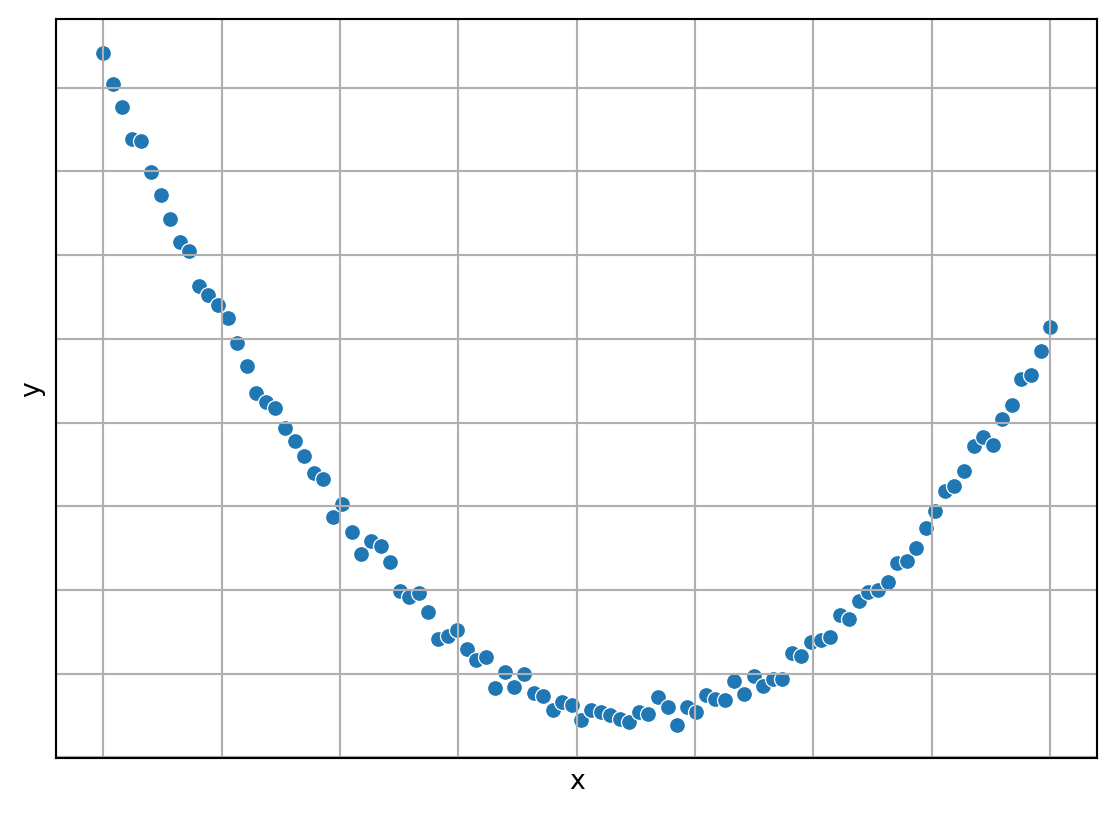
El problema de regresión es muy conocido y seguramente ya se imaginaron que la respuesta sería encontrar los parámetros de una parábola. La Figura 1.9 muestra una visualización del regresor, mostrado en color negro y los datos de entrenamiento en color azul.
Código
sns.lineplot(data=df, x='x', y='y', legend=False, color='k')
fig = sns.scatterplot(data=df, x='x', y='ym', legend=False)
fig.tick_params(axis="both", which="both", bottom=False,
top=False, left=False, right=False,
labelbottom=False, labelleft=False)
fig.set(xlabel='x', ylabel='y')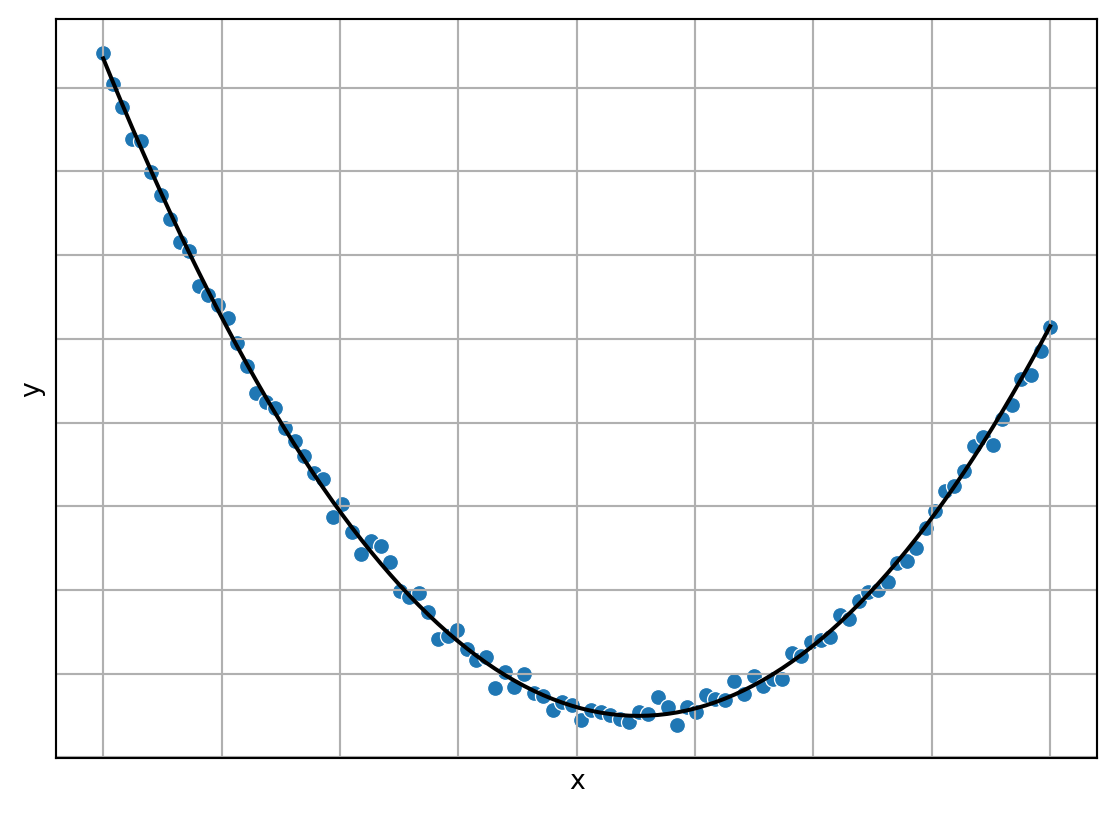
Al igual que en aprendizaje no supervisado, este ejercicio de visualización no es posible en todos los problemas de aprendizaje supervisado, pero si permite ganar intuición sobre la forma en que trabajan estos algoritmos.
1.5 Definiciones de Aprendizaje Supervisado
El primer paso es empezar a definir los diferentes conjuntos con los que se trabaja en aprendizeje computacional. Todo inicia con el conjunto de entrenamiento identificado en este documento como \(\mathcal T\). Este conjunto se utiliza para estimar los parámetros o en general buscar un algoritmo que tenga el comportamiento esperado.
Se puede asumir que existe una función \(f\) que genera la relación entrada salida mostrada en \(\mathcal T\), es decir, idealmente se tiene que \(\forall_{(x, y) \in \mathcal D} f(x) = y\). En este contexto, aprendizaje supervisado se entiende como el proceso de encontrar una función \(h^*\) que se comporta similar a \(f\).
Para encontrar \(h^*\), se utiliza \(\mathcal T\); el conjunto de hipótesis (funciones), \(\mathcal H\), que se considera puede aproximar \(f\); una función de error, \(L\); y el error empírico \(E(h \mid \mathcal T) = \sum_{(x, y) \in \mathcal T} L(y, h(x))\). Utilizando estos elementos la función buscada es: \(h^* = \textsf{argmin}_{h \in \mathcal{H}} E(h \mid \mathcal T)\).
El encontrar la función \(h^*\) no resuelve el problema de aprendizaje en su totalidad, además se busca una función que sea capaz de generalizar, es decir, que pueda predecir correctamente instancias no vistas. Considerando que se tiene un conjunto de prueba, \(\mathcal G=\{(x_i, y_i)\}\) para \(i=1 \ldots M\), donde \(\mathcal T \cap \mathcal G = \emptyset\) y \(\mathcal T \cup \mathcal G = \mathcal D.\) La idea es que el error empírico sea similar en el conjunto de entrenamiento y prueba. Es decir \(E(h^* \mid \mathcal T) \approx E(h^* \mid \mathcal G)\).
El conjunto de prueba \(\mathcal{G}\) se utiliza para medir el error empírico y comparar el rendimiento de diferentes algoritmos, permitiendo seleccionar el que tenga las mejores características. La Figura 1.10 muestra el rendimiento utilizando el promedio de la cobertura (macro-recall, ver Capítulo 4). En la figura se observa el rendimiento de clasificadores Gaussianos Ingenuo, LDA y QDA (Capítulo 3), Máquinas de Soporte Vectorial lineal (M.S.V., ver Capítulo 9), Vecinos Cercanos (Capítulo 7) y Árboles Aleatorios (Capítulo 12). Se destaca que la M.S.V. presentó el mejor rendimiento, aunque estadísticamente es equivalente a algunos algoritmos marcados con la etiqueta Equivalente y es estadísticamente mejor que otros algoritmos marcados con la etiqueta Diferente.
Código
bioresponse = fetch_openml(data_id=1464)
y = bioresponse.target.to_numpy()
D = bioresponse.data.to_numpy()
Xtrain, Xtest, ytrain, ytest = train_test_split(D, np.array(y), random_state=13)
names = ['Ingenuo', 'LDA', 'QDA', 'M.S.V', 'Vecinos', 'Bosques']
algs = [GaussianNB(), LDA(), QDA(),
make_pipeline(Normalizer(), LinearSVC(class_weight='balanced')),
KNeighborsClassifier(),
RandomForestClassifier(class_weight='balanced')]
score = recall_score(ytest, average='macro', use_tqdm=False)
for name, alg in zip(names, algs):
alg.fit(Xtrain, ytrain)
score(alg.predict(Xtest), name=name)
score.plot(value_name='Cobertura (promedio)', alg_legend='Algoritmos',
comp_legend='Comparación',
winner_legend='Mejor',
tie_legend='Equivalente',
loser_legend='Diferente')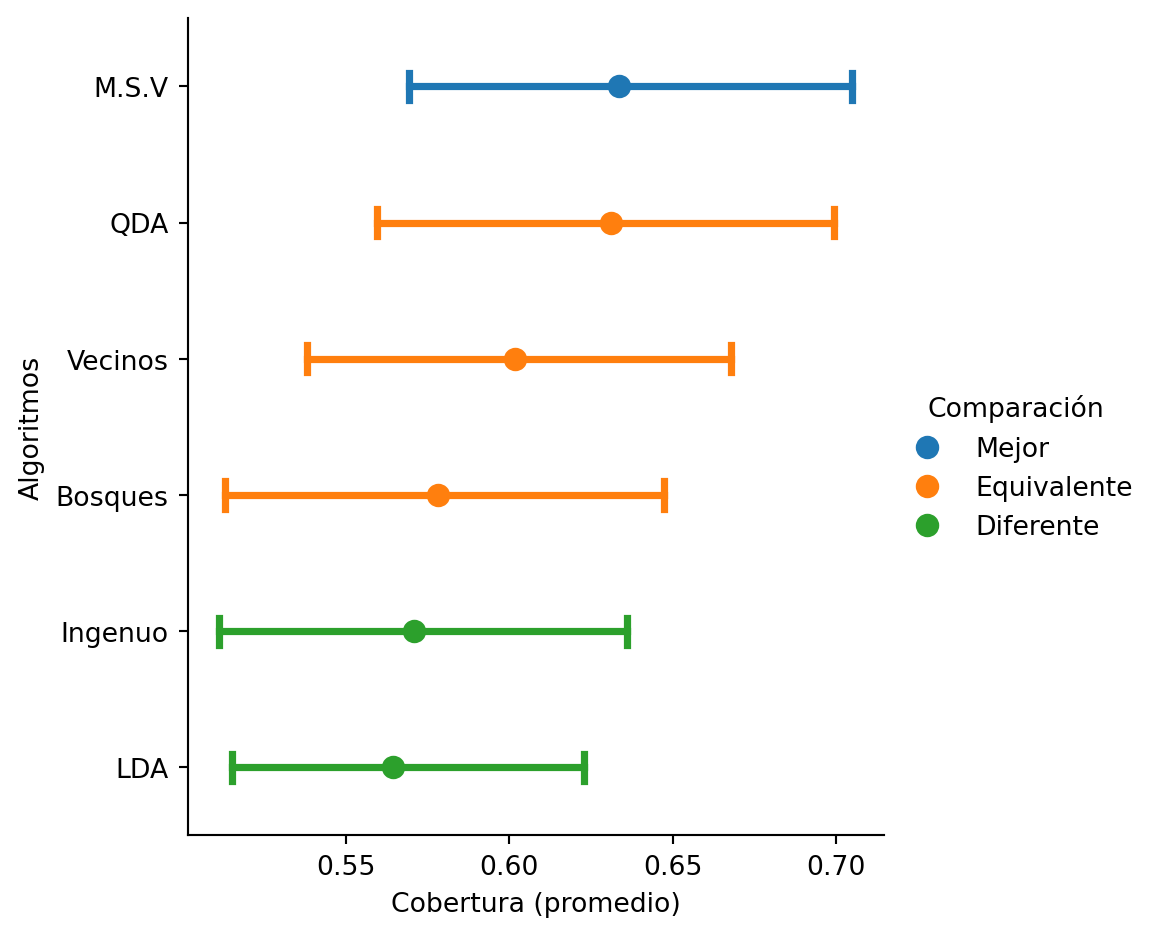
1.5.1 Estilos de Aprendizaje
Utilizando \(\mathcal T\) y \(\mathcal G\) podemos definir inductive learning como el proceso de aprendizaje en donde solamente se utiliza \(\mathcal T\) y el algoritmo debe de ser capaz de predecir cualquier instancia. Por otro lado, transductive learning es el proceso de aprendizaje donde se utilizar \(\mathcal T \cup \{ x \mid (x, y) \in \mathcal G \}\) para aprender y solamente es de interés el conocer la clase o variable dependiente del conjunto \(\mathcal G\).
1.5.2 Sobre-aprendizaje
Existen clases de algoritmos, \(\mathcal H\), que tienen un mayor grado de libertad el cual se ve reflejado en una capacidad superior para aprender, pero por otro lado, existen problemas donde no se requiere tanta libertad, esta combinación se traduce en que el algoritmo no es capaz de generalizar y cuantitativamente se ve como \(E(h^* \mid \mathcal T) \ll E(h^* \mid \mathcal G)\).
Para mostrar este caso hay que imaginar que se tiene un algoritmo que guarda el conjunto de entrenamiento y responde lo siguiente:
\[h^*(x) = \begin{cases} y & \text{si} (x, y) \in \mathcal T\\ 0 & \end{cases}\]
Es fácil observar que este algoritmo tiene \(E(h^* \mid \mathcal T) = 0\) dado que se aprende todo el conjunto de entrenamiento.
La Figura 1.11 muestra el comportamiento de un algoritmo que sobre-aprende, el algoritmo se muestra en la línea negra, la línea azul corresponde a una parábola (cuyos parámetros son identificados con los datos de entrenamiento) y los datos de entrenamiento no se muestran (se pueden observar en la Figura 1.8); estos corresponden a una parábola mas un error gaussiano. Entonces podemos ver que la línea negra pasa de manera exacta por todos los datos de entrenamiento y da como resultado la línea negra que claramente tiene un comportamiento más complejo que el comportamiento de la parábola que generó los datos.
Código
arbol = tree.DecisionTreeRegressor().fit(np.atleast_2d(x).T, ym)
hy = arbol.predict(np.atleast_2d(x).T)
df['arbol'] = hy
sns.lineplot(data=df, x='x', y='arbol', legend=False, color='k')
fig = sns.scatterplot(data=df, x='x', y='y', legend=False)
fig.tick_params(bottom=False, top=False,
left=False, right=False,
labelbottom=False, labelleft=False)
fig.set(xlabel='x', ylabel='y')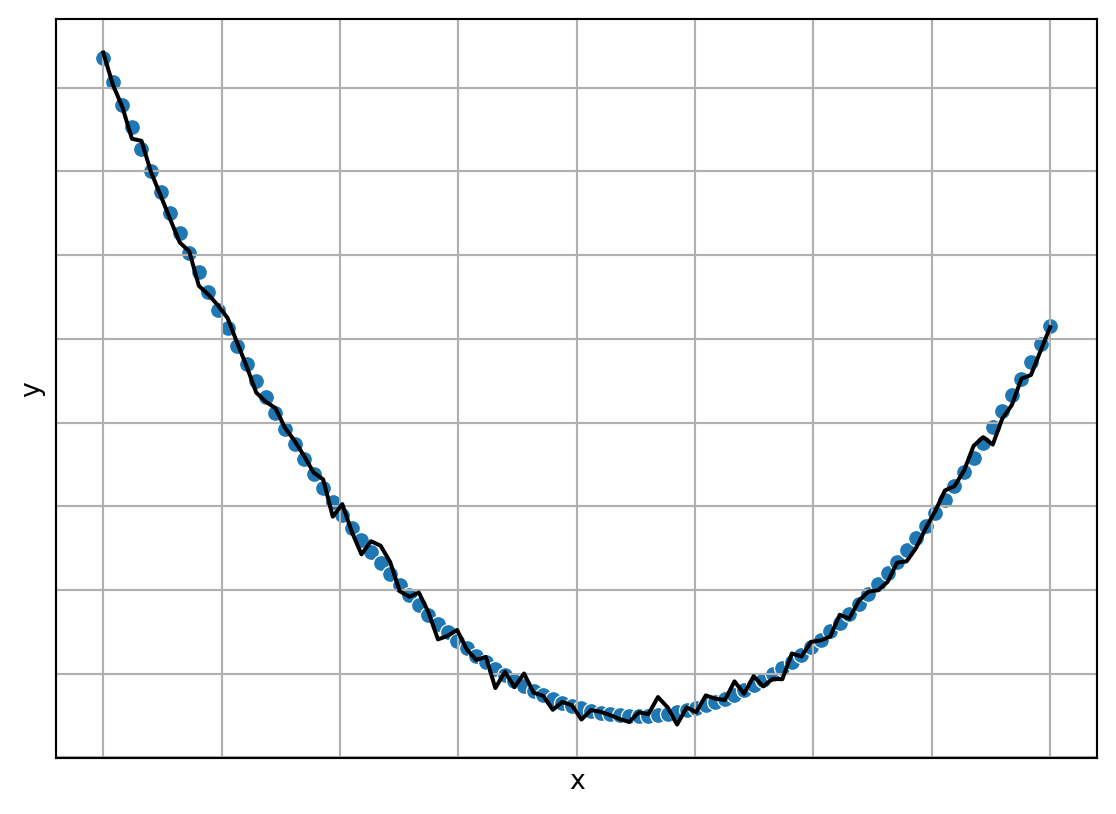
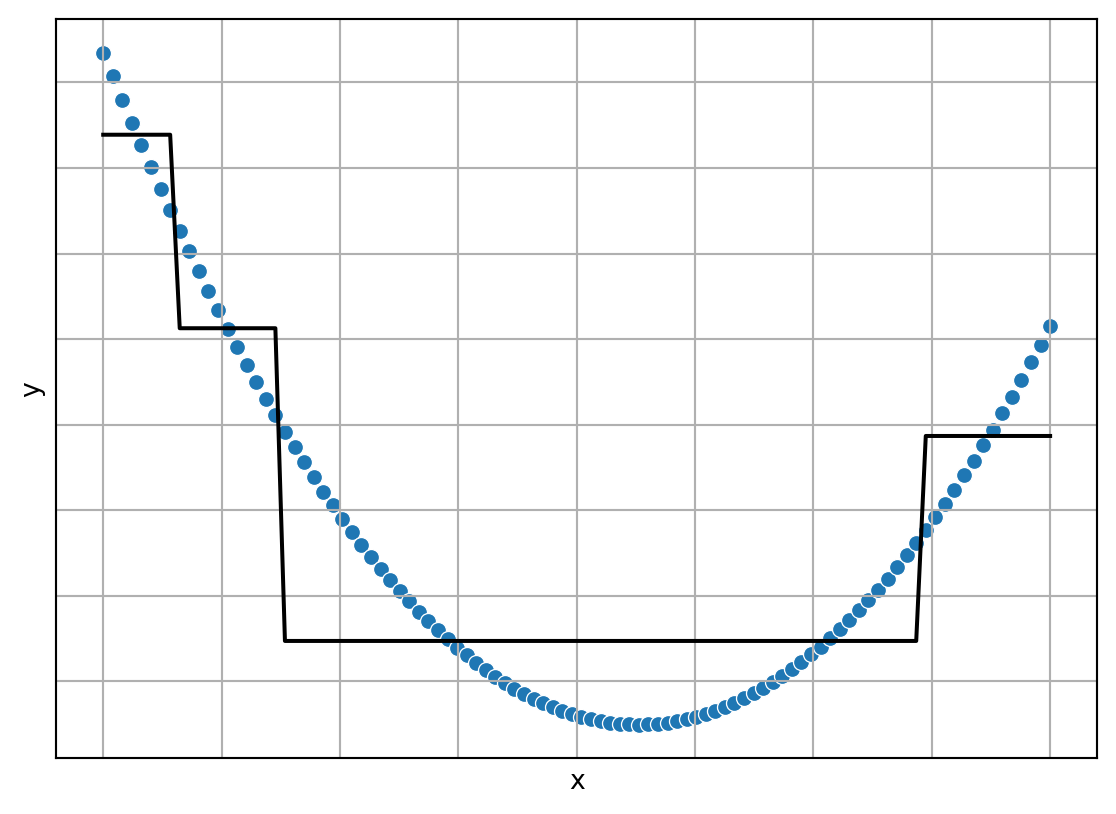
1.5.3 Sub-aprendizaje
Por otro lado existen problemas donde el conjunto de algoritmos \(\mathcal H\) no tienen los grados de libertad necesarios para aprender, dependiendo de la medida de error esto se refleja como \(E(h^* \mid \mathcal T) \gg 0\). La Figura 1.12 muestra un problema de regresión donde el algoritmo de aprendizaje presenta el problema de sub-aprendizaje.
Código
arbol = tree.DecisionTreeRegressor(max_depth=2).fit(np.atleast_2d(x).T, ym)
hy = arbol.predict(np.atleast_2d(x).T)
df['arbol'] = hy
sns.lineplot(data=df, x='x', y='arbol', legend=False, color='k')
fig = sns.scatterplot(data=df, x='x', y='y', legend=False)
fig.tick_params(bottom=False, top=False,
left=False, right=False,
labelbottom=False, labelleft=False)
fig.set(xlabel='x', ylabel='y')